市面上論述量化交易的中文著作不多,講台股的更少,葉怡成教授去年出版的「台股研究室」是鳳毛麟角的大作,以各種選股因子與模型回測最近12年的台灣股市,
全面檢視台股投資的方法。涵蓋價值因子、獲利因子、風險因子、規模因子、慣性因子,分析全面,回測與分析的注意事項也有點到,針對單因子和多因子策略作探討,比較可惜的是該書無提供相關代碼,這點Finlab課程的內容剛好可以補上,利用Python課程的技巧親身實作葉教授的分析,驗證的同時,更能內化書中的內容,改良成屬於自己的策略。這一系列會從單因子開始實作。
風險因子理論基礎
參考台股研究室Ch.10 & 維基百科
“””
在投資學上,風險指的是報酬率的不確定性,總風險由非系統風險和系統性風險組成。
非系統風險為特定公司發生的風險,例如罷工、火災、經理人背信等等,可透過多元化投資組合抵銷。
系統風險發生於企業外部,無法被多元化投資組合抵銷,也稱作市場風險,系統風險的大小可用
beta係數利用回歸的方法計算,可簡單歸類:
beta係數絕對值等於1即證券的價格與市場一同變動。
beta係數絕對值高於1即證券價格比總體市場更波動。
beta係數絕對值低於1即證券價格的波動比市場為低。
如果beta =0表示沒有風險。
其他相關理論內容可自行參考書籍或網站資料
“””
投資組合Beta實作
完整程式碼連結置底。
帶入投資組合標的與權重、還原股價、benchmark資料即可做成,這邊使用發行量加權報酬指數,使用python內建的統計套件“from scipy import stats”的linregress(線性回歸)計算出beta和alpha,
tickers = ['1101', '2330', '6261', '6263', '9939']
weights = [0.1,0.2,0.25,0.25,0.2]
def get_alpha_beta(tickers:list,weights:list,start_date=None,end_date=None,limit=None,price_data=None,benchmark_ret=None,plot=False):
if price_data is None:
price_data =data.get_adj()
price_data = price_data[tickers]
if start_date:
price_data = price_data[price_data.index >= start_date]
if end_date:
price_data = price_data[price_data.index <= end_date]
if limit:
price_data = price_data.iloc[-limit:]
ret_data = price_data.replace(0,np.nan).fillna(method='ffill').pct_change()[1:]
port_ret = (ret_data * weights).sum(axis = 1)
if benchmark_ret is None:
benchmark_ret=data.get('benchmark_return:發行量加權股價報酬指數').pct_change()[1:].loc[port_ret.index].iloc[:,-1]
if plot:
df=pd.concat([benchmark_ret, port_ret], axis=1)
df.columns=['benchmark','port']
sns.regplot(x='benchmark',y='port',data=df)
plt.xlabel("Benchmark Returns")
plt.ylabel("Portfolio Returns")
plt.title("Portfolio Returns vs Benchmark Returns")
plt.show()
beta, alpha = stats.linregress(benchmark_ret.values,port_ret.values)[:2]
return beta, alpha
get_alpha_beta(tickers,weights,'2020-1-1','2021-4-30',plot=True)
Beta 選股策略
台股研究室採用T+2季做為財報消息公布後的進場點,Q1-Q4分別在同年
7月、同年11月、隔年1月、隔年4月的1日進場,避免先視偏差,採取比較延遲進場的保守作法,實務上一般人也很難跟消息跟很緊,這樣的設定是合理的。
選股與回測策略條件如下
1. beta以進場日前200天計算。
2. 每回合持有一季,不帶入稅費計算,主要看分組趨勢。
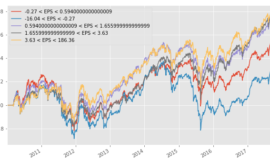
3. 參考台股研究室,beta分10組,分組的數值由大到小,第1組為beta最大前10%,第10組為beta最小的10%,以此類推。分組回測主要是方便觀察單因子是否為單調線性,若是,策略效果較顯著,若為曲折線型,則參考度較小。
程式細節:
使用pandas的rank與cut分組,cut比較少在使用,執得認識一下。
https://pandas.pydata.org/docs/reference/api/pandas.cut.html
beta_cal_range=200
now = datetime.now().strftime("%Y-%m-%d")
dates=pd.date_range(start='2008-1-1', end=now , freq='3MS')
df_set=[]
for date in dates:
print(f'process {date}')
price_data =data.get_adj()
port_ret = price_data[price_data.index < date].replace(0,np.nan).fillna(method='ffill').pct_change()[1:].iloc[-beta_cal_range:].dropna(axis=1)
benchmark_ret=data.get('benchmark_return:發行量加權股價報酬指數').pct_change()[1:].loc[port_ret.index].iloc[:,-1]
df=pd.DataFrame([{'stock_id':i,'beta':stats.linregress(benchmark_ret.values,port_ret[i])[0] } for i in port_ret.columns])
df['date']=date
df['beta_rank']=df['beta'].rank(pct=True)
labels=[str(i) for i in range(10,0,-1)]
df['label']=pd.cut(df['beta_rank'],bins=[i/10 for i in range(0,11,1)], labels=labels)
df_set.append(df)
df_all=pd.concat(df_set)
label_group=df_all.copy()
label_group=label_group.set_index(['stock_id','date'])
add_profit_prediction(label_group)
label_group=label_group.groupby(['date','label'])[['beta','return']].mean()
label_group=label_group.dropna()
label_group=label_group.reset_index()
label_group['cumprod_return']=label_group.groupby(['label'])[['return']].cumprod()
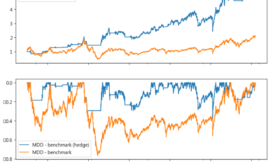
label_group回測結果





結論
實作出來的結果與葉教授書中圖片的結果相似,單因子策略有效。證實冒著較高的風險,不一定報酬較高,反而冒著較低的波動風險,長期能獲得較好的績效。相關結果的解釋可參閱書中內容。
beta大的台股投組放中長期小心閃尿啊,瘋狗流愛抓高beta的,停損要設好,長期凹下場不好。中長期投組可納入風險因子當作篩選因子,低波動進場,放著好安心。
beta單因子策略即始劃分10組,用最小beta的投資仍有百檔標的,需要進一步搭配其他因子減少標的和優化,考量流動性問題,將第9組一併納入可減少部分流動性風險。
colab程式連結
供各位先進參考