前情提要
在建構出自己的 Smart ETF 00905 2.0!Part 2 – 程式驗證實作中,說明了每項選股條件的細節與程式實作方法,並剔除有關流動性檢驗的所有限制,以便更貼近驗證Smart多因子效度的目的。
我們還原出 Smart ETF 00905 的選股條件回測後,發現報酬率優於大盤,但最大交易回落(MMD)並不理想,推測因子的效度可能參差不齊。因此我們進行了所有細項單因子的回測,從總報酬率、熱力圖、線性回歸得出的相關性來檢驗每個因子的效度。

簡介
此篇將會搭配前篇細項的單因子分析進行以下三步驟的優化:
- 測試不同市場表現
- 組合有效的單因子、剔除無用因子
- 限縮持股數目
每一項優化的結果將做為下一項優化的輸入,因此在前兩個步驟中,若績效相近則會選擇較寬鬆的選股條件以保留較多的股票數目,以便後續的優化順利進行。
優化策略 – 步驟設計
不同市場表現
00905將母體限定為上市公司,代表只有上市公司有機會被納入ETF中,推測此設計是為了避免流動性問題,但或許Smart多因子策略更適合上市公司也不無可能。
因此優化的第一步是檢驗在不同市場中Smart多因子策略的績效表現,進而選出最適合Smart多因子策略的市場。若報酬率沒有大幅度的變化,再將母體從上市公司放寬到上市+上櫃,增加選股標的以利後續優化。
組合有效單因子
這個階段要剔除效度不高的因子來降低輸入的維度,目的是減少雜訊以及過擬和(overfitting)的可能性。
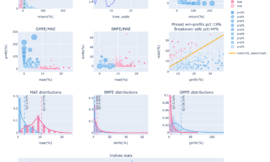
觀察下方的單因子相關性圖表,前三名的相關性較為突出,之後的差距則較不明顯。因此將取相關性前三名,重新計算權重,並以後三名作為對照組,比較兩者在各時間段的表現,實驗篩選後的單因子是否能優化目前的策略。

限縮持股數目
經過前兩步驟後,假設我們已經得到一個效度相當不錯的策略。若是一個優秀的選股策略,持股的數目應該會與報酬率成反比。當選股條件越嚴苛,持股的數目越少時,報酬率會越好,整體會呈現大致線性的趨勢。
然而當持股數目小到一定程度時,會由於樣本數的不足導致大幅度的績效變化,因此要用持股數目對報酬率作圖,檢驗策略是否有足夠卓越的分群效果,並找出這個策略隨最適合的持股數目為何。
優化策略 – 程式實作
不同市場表現
將市場區分為三個類別:上市、上櫃、上市+上櫃,並在訓練集和測試集中比對報酬率曲線圖。
在上篇文章中,計算已經是全部股票的多因子權重,因此現在只需要跟上櫃的股票取交集,所得到的就是上櫃版本的Smart多因子策略。
程式碼
# 取得上櫃columns
with data.universe(market='OTC',category='金融'):
financialOtcColumns =data.get('price:收盤價').columns
with data.universe(market='OTC'):
allOtcColumns =data.get('price:收盤價').columns
# 上櫃 (training)
col = 多因子權重係數.columns.intersection(allOtcColumns)
多因子權重係數_OTC = 多因子權重係數[col]
cond = 多因子權重係數_OTC < 多因子權重係數_OTC.quantile_row(0.75) #計算多因子權重係數小於75分位數的股票
多因子權重係數_OTC[cond] = 0 # 設權重為0
position = 多因子權重係數_OTC.loc[:"2020-08-10"]
position.dropna(how="all",inplace=True)
report = backtest.sim(position, resample=None,fee_ratio=0,tax_ratio=0,upload=False)
report.benchmark = data.get('benchmark_return:發行量加權股價報酬指數').squeeze()
report.display()回測結果


無論在訓練集或測試集,績效表現皆是上市>上市+上櫃>上櫃,但彼此間的報酬率差異並不顯著,像2020/03~2021/04這段期間報酬率幾乎貼合。考量到目前只是第一步驟,為了些微的報酬率提升,刪除近800家上櫃公司的代價太高了點。
權衡之下決定將母體放寬至上市+上櫃公司,往下一步驟繼續進行優化。
組合有效單因子
分別將前三名、後三名進行Z-transform之後取平均分數,再按照00905定義的權重轉換公式將分數轉換成權重即可,資料使用測試集進行回測,因此回測日期從指數編纂上市當天開始到目前為止。
註:使用index_str_to_date()將季度資料轉換成日週期統一進行回測。
程式碼
# 相關性前三名(益本比、營利動能、股價動能)
scoreTop3 = (Z(益本比) + Z(營利動能) + Z(股價動能))/3
col = scoreTop3.columns.intersection(allColumns)
scoreTop3 = scoreTop3[col].applymap(lambda z: 1+z if(z>=0) else (1-z)**-1)
cond = scoreTop3 <= scoreTop3.quantile_row(0.75)
scoreTop3[cond] = 0
position = scoreTop3.index_str_to_date().loc["2020-08-10":]
report1 = backtest.sim(position, resample=None,fee_ratio=0,tax_ratio=0,upload=False)
# 相關性後三名(收益變動率、槓桿度、股東收益率)
scoreLast3 = (Z(收益變動率)+Z(槓桿度)+Z(股東收益率))/3
col = scoreLast3.columns.intersection(allColumns)
scoreLast3 = scoreLast3[col].applymap(lambda z: 1+z if(z>=0) else (1-z)**-1)
cond = scoreLast3 <= scoreLast3.quantile_row(0.75)
scoreLast3[cond] = 0
position = scoreLast3.index_str_to_date().loc["2020-08-10":]
report2 = backtest.sim(position, resample=None,fee_ratio=0,tax_ratio=0,upload=False)
# Benchmark (原策略)
col = 多因子權重係數.columns.intersection(allColumns)
scoreBenchmark = 多因子權重係數[col]
cond = scoreBenchmark < scoreBenchmark.quantile_row(0.75) #計算多因子權重係數小於75分位數的股票
scoreBenchmark[cond] = 0 # 設權重為0
position = scoreBenchmark.index_str_to_date().loc["2020-08-10":]
report3 = backtest.sim(position, resample=None,fee_ratio=0,tax_ratio=0,upload=False)
# 作圖
plt.plot(report1.creturn,label="前三名因子")
plt.plot(report2.creturn,label="後三名因子")
plt.plot(report3.creturn,label="原策略")
plt.title("不同市場報酬率曲線(Testing set)")
plt.legend()
plt.show()回測結果
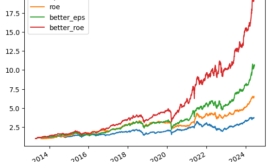
從測試集的報酬率曲線觀察,篩選後的單因子所組成的策略要優於原先的策略,並大幅度的勝過後三名的策略。因子並不是越多越好,而應該擷取其中的精華,去除無效的因子,對策略作進一步的簡化,如此一來反而能獲得更佳的結果。
由於回測結果理想,策略將精簡到由前三名的細項單因子組成(益本比、營利動能、股價動能),繼續往下一步進行優化。

限縮持股數目
使用百分位數quantile_row()來限縮股票數目,大於0%等同於大盤、大於99%則代表只取分數前1%的股票。分為訓練集和測試集,各自從0%一路回測到99%,並畫出圖表觀察報酬率隨百分位數的變化。
程式碼
# 最佳化持股百分位數 (限縮持股)
creturnTrainDf = pd.DataFrame()
creturnTestDf = pd.DataFrame()
score = (Z(益本比) + Z(營利動能) + Z(股價動能))/3
col = score.columns.intersection(allColumns)
score = score[col].applymap(lambda z: 1+z if(z>=0) else (1-z)**-1)
for i in range(0,100,1):
cond = score > score.quantile_row(i/100)
position = score[cond].index_str_to_date().loc[startDate:"2020-08-10"]
position.dropna(how="all",inplace=True)
report = backtest.sim(position, resample=None,fee_ratio=0,tax_ratio=0,upload=False)
creturnTrainDf[str(i)+"%"] = report.creturn
position = score[cond].index_str_to_date().loc["2020-08-10":]
position.dropna(how="all",inplace=True)
report = backtest.sim(position, resample=None,fee_ratio=0,tax_ratio=0,upload=False)
creturnTestDf[str(i)+"%"] = report.creturn
# print(i/100)
# 作圖
plt.title("不同持股數目報酬率曲線(Training set)")
plt.plot(creturnTrainDf.iloc[-1,:])
plt.xticks(["0%","10%","20%","30%","40%","50%", "60%", "70%", "80%","90%","100%"])
plt.show()
plt.title("不同持股數目報酬率曲線(Testing set)")
plt.plot(creturnTestDf.iloc[-1,:])
plt.xticks(["0%","10%","20%","30%","40%","50%", "60%", "70%", "80%","90%","100%"])
plt.show()回測結果
訓練集、測試集都隨著選股標準越來越嚴格、選出的股票越來越少,報酬率也隨之不斷上升,曲線十分平滑,這是很好的現象!
這邊發生一個特殊的現象,當百分位數來到85%以上之後,訓練集和測試集的表現都變的非常不穩定,呈現上下暴衝的失控狀態。


別擔心!這是選出太少股票時很容易遇到的問題,由於持有的股票太少,導致每隻股票都佔據資產組合中相當大的部位,因此當其中的任何股票遭遇變動,都會大幅度的影響到整體策略的績效報酬。
換句話說,當樣本數太少時,會導致策略沒辦法達到本身的期望值,而是更多取決於機率和運氣。因此當回測報酬率相差不大、資金充裕的時候,會建議分散持有更多的股票而不是重壓少數幾檔股票,來避免可能遭遇的風險。
以此策略為例,雖然從訓練集來看,99%會是最好的參數,但在資金充裕的情況下會建議最高設定到85%~95%就好,能有效降低風險發生的機率。
Smart ETF 00905 優化前後對比
最後做一個統整性的比較,將加權指數、上市特選Smart多因子指數、去除流動性限制後的Smart多因子策略、優化後的多因子策略的報酬率曲線做疊圖,觀察其中走勢的差異。
註:各類指數皆收錄在data.get('stock_index_price:收盤指數'),可以隨時使用
程式碼
# 最終結果
cond = score > score.quantile_row(93/100)
position = score[cond].index_str_to_date().loc["2020-08-10":]
position.dropna(how="all",inplace=True)
report1 = backtest.sim(position, resample=None,fee_ratio=0,tax_ratio=0,upload=False)
# 最初結果
position = 多因子權重係數_TSE.index_str_to_date().loc["2020-08-10":]
report2 = backtest.sim(position, resample=None,fee_ratio=0,tax_ratio=0,upload=False)
# 上市特選Smart多因子指數 (00905追蹤之指數)
smartIndex = index["上市特選Smart多因子指數"].dropna() / index["上市特選Smart多因子指數"].dropna()[0]
# 加權指數
TAIEX = data.get('benchmark_return:發行量加權股價報酬指數').loc["2020-08-10":] / data.get('benchmark_return:發行量加權股價報酬指數').loc["2020-08-10"][0]
# 作圖
plt.title("優化前後報酬率曲線(Testing set)")
plt.plot(report1.creturn,label="多因子策略(去除流動性濾網+優化)")
plt.plot(report2.creturn,label="多因子策略(去除流動性濾網)")
plt.plot(smartIndex,label="特選Smart多因子指數")
plt.plot(TAIEX,label="加權指數")
plt.legend(loc='upper left')
plt.show()回測結果

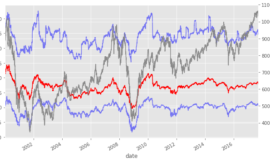
若不去除流動性的限制,Smart多因子指數與加權指數十分相似,但一去除流動性的限制報酬率馬上增加許多,之後則繼續透過單因子的分析和縮減持股數目,進一步的優化,提高總報酬率。
結論
回測結果驗證了熱門股票ETF根本性的缺陷文章所說:「流動性始終是熱門ETF最大的缺陷,當ETF規模越大,就越難獲得超額報酬。」
本次系列文章以近期發行的00905為例,我們解析了ETF的公開說明書、模擬ETF撰寫選股策略、去除流動性限制,隨後進行一系列的策略優化,包括檢驗不同市場的表現、篩選有效單因子、限縮持股數目,最後得到一個不需要管理費、報酬率更高的 00905 2.0版本!
這次的文章更偏向實驗的性質,目的是讓大家了解finlab更多的可能性,同時也是希望鼓勵大家自行嘗試使用不同的ETF來實作,因此沒有考慮手續費、實際買賣的資金大小等等限制。優化的方法也還有許多種,像是加入嘗試單因子彼此間搭配的效果、單因子權重的搭配、加入finlab文章中介紹的因子補齊弱項等等……有待大家繼續往下研究,希望大家都能寫出專屬於自己的ETF,獲取超額報酬!
那這次的研究就到這邊結束啦!窩4阿榤,我們下次見!