前陣子韓老師線上直播時,有同學許願想幫標的打分數,利用分數來篩選。

今天FinLab的神燈精靈就來幫你實現願望,示範如何用 pandas 撰寫指標計分,並實際應用到策略開發。
方法一、Pandas qcut
qcut 是 Pandas模組中基於分位數的離散化函數。剛好適用這位同學的需求。簡單打個範例來看看qcut的效果。
import pandas as pd
# range(20)數列按10分位數切分級
pd.qcut(x=range(20), q=10, labels=False)
# output
# array([0, 0, 1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9])從以下範例中,可以得知x參數為要處理的1維序列資料 ; q為分級的設定 ; label如果為 False,則返回整數分級。
輸出結果將 1-20 的序列分成 10 等份,注意分級從 0 開始。
認識了qcut以後,我們要將該函數應用到FinLab的資料格式,就可以得到財務指標分級資料。
with data.universe(market='TSE_OTC'):
df = data.get('fundamental_features:ROE稅後')
rank_df = df.T
for date in rank_df.columns:
# 方便認知,將0~9變1~10
rank_df[date] = pd.qcut(rank_df[date].rank(method='first'), 10, labels=False)+1
rank_df = rank_df.T方法二、程式簡化
但 qcut 函數有個缺點是他不適用 DataFrame 資料型態,只能用在序列,所以我們要一行行操作再組裝,程式碼變的瑣碎。
其實我們能用 rank 函數直接去做簡化,運用函數的axis參數做整列分級運數,pct參數將數值轉成百分位數以方便之後使用 mul 方法將數據乘上欲分級距,得數值後再將數據全+1,讓最小分級從1開始,而不是0開始,最後使用「無條件捨去法 (np.floor)」取得級距值。
最後由於排第一名的會跑到多出來的 rank (因為只有他是滿分 1 分),所以要加上clip去限縮分數上限,ex:若用10等分級距,第一名會是11分,用clip讓數據限縮到10分內。
程式範例如下:
with data.universe(market='TSE_OTC'):
rank_df = (data.get('fundamental_features:ROE稅後')
.rank(axis=1, pct=True, ascending=True)
.mul(10)
.add(1)
.apply(np.floor).clip(0,10))程式是不是變乾淨很多呢?
函數封裝
def qcut_feature(data_name='fundamental_features:ROE稅後', q_range=10, ascending=True):
import numpy as np
rank_df = (data.get(data_name)
.rank(axis=1, pct=True, ascending=ascending)
.mul(q_range)
.add(1)
.apply(np.floor).clip(0,q_range))
return rank_df
參數說明如下:
- data_name:設定要處理的FinLab資料庫中的財務指標。
- q_range:變數設定分割的級距。
- ascending:的用途在有些指標我們希望數值越高則分數越高,如ROE ; 有些指標我們希望數值越低則分數越高,如負債比率,所以用 ascending 來控制指標升降屬性,ascending=False時,會反轉序列排序,產生數值越低則分數越高的作用。
來執行程式並來檢視一下數據吧!可以發現護國神山的 ROE 長年都在前段班。
roe_score = qcut_feature(data_name='fundamental_features:ROE稅後')
roe_score['2330'].plot()
策略開發
from finlab import data
from finlab.backtest import sim
def qcut_feature(data_name='fundamental_features:ROE稅後', q_range=10, ascending=True):
import numpy as np
rank_df = (data.get(data_name)
.rank(axis=1, pct=True, ascending=ascending)
.mul(q_range
.add(1)
.apply(np.floor).clip(0,q_range))
return rank_df
with data.universe(market='TSE_OTC'):
# 預想越高越好
roe_score = qcut_feature(data_name='fundamental_features:ROE稅後')
營業毛利率_score = qcut_feature('fundamental_features:營業毛利率')
稅前淨利年增率_score = qcut_feature('fundamental_features:稅前淨利成長率')
應收帳款週轉率_score = qcut_feature('fundamental_features:應收帳款週轉率')
# 預想越低越好
負債比率_score = qcut_feature('fundamental_features:負債比率',ascending=False)
all_score = roe_score + 營業毛利率_score + 稅前淨利年增率_score + 應收帳款週轉率_score + 負債比率_score
# 設定總分要求
position = all_score >= 40
report = sim(position,resample='M',position_limit=0.1,name="財務指標計分回測範例",upload=True)利用前述的qcut_feature函數,範例用5個財報指標來計分,並將分數加總。
策略條件要求總分要高於40分,也就是平均一個分數要達8分以上,算是不低的要求。
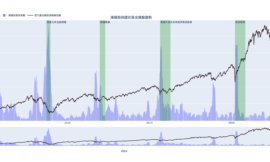
如果只用此指標做月週期回測,結果如下,報酬率比大盤優一點點,每月檔數穩定會選到100檔上下。

優化
標的數量偏多,實際上我們資金有限,買不了那麼多,這時我們可以想想,同樣的財務指標總分下,越低價的股票是不是越有上漲的空間呢?
from finlab import data
from finlab.backtest import sim
def qcut_feature(data_name='fundamental_features:ROE稅後', q_range=10, ascending=True):
import numpy as np
rank_df = (data.get(data_name)
.rank(axis=1, pct=True, ascending=ascending)
.mul(q_range)
.add(1)
.apply(np.floor).clip(0,q_range))
return rank_df
with data.universe(market='TSE_OTC'):
# 預想越高越好
roe_score = qcut_feature(data_name='fundamental_features:ROE稅後')
營業毛利率_score = qcut_feature('fundamental_features:營業毛利率')
稅前淨利年增率_score = qcut_feature('fundamental_features:稅前淨利成長率')
應收帳款週轉率_score = qcut_feature('fundamental_features:應收帳款週轉率')
# 預想越低越好
負債比率_score = qcut_feature('fundamental_features:負債比率',ascending=False)
all_score = roe_score + 營業毛利率_score + 稅前淨利年增率_score + 應收帳款週轉率_score + 負債比率_score
# 設定總分要求
position = all_score >= 40
# 選前10低價股
close = data.get('price:收盤價')
position = (position*close).astype(float)
position = position[position>0].is_smallest(10)
report = sim(position,resample='M',position_limit=0.1,name="財務指標計分回測範例",upload=True)
所以我們上面程式後段再從原先清單選出每期股價前 10 低的條件,則報酬率明顯拉出差距,也更貼近小資族的使用情境。

結論
qcut 是不是很好用呢?又認識一個pandas的新工具!
附上colab範例檔讓大家練習~來試試打造自己的指標計分策略吧!