本文中產生了 1000 組多空財務指標,並且利用財務指標進行多空對沖策略,回測績效高達年報酬 30%!在全球資本市場中,美國股市佔據著不可忽視的地位,其規模與活躍度長期以來都是全球最領先的。尤其在科技、金融和消費等多個重要行業,美股市場都匯聚了眾多具有全球影響力的領先企業。對投資者而言,深入了解並善用財務指標來分析和評估美股市場的投資機會,是提高投資效益、降低投資風險的重要手段。FinLab 網站中有一個 財報 20 大的選股 策略,是否能夠用在美股之中呢?效果如何呢?就讓我們來研究研究。
美股策略研究簡單嗎?
財務指標是反映企業經營狀況、財務健康和投資價值的重要工具。透過財務指標的分析,我們可以更加清晰地理解企業的盈利能力、資產負債狀態、營運效率以及現金流狀況,從而作出更為理性和科學的投資決策。然而當前美股已經有非常多的量化交易團隊與機構從中找尋超額報酬,所以我們在實驗中,發現並沒有像是台股一樣簡單做得出好策略。
台股美股的差異?
台股一般來說,我們用均線濾網就可以很有效的篩選股票,用 EPS 一定是要找 EPS 每季上升的的股票標的。然而在美股竟然發生一百八十度的轉變,例如,美股跟台股在均線的使用上,幾乎是完全相反,也就是很容易有均線回歸,漲多了就跌回去的狀況發生。而創新高的 EPS 不要以為接下來股價也會創新高,因為當天股價可能都已經反應完畢了,甚至過度反應而導致超漲。
美股的財報指標還有用嗎?
這就是這篇文章想要來探討的,我們使用 quandl 所有的美股指標,來預測看看究竟是否有能力做出不錯的策略。假如你是 VIP 會員,可以參考我們的財務指標 20 大策略,並且嘗試換成美股版本喔!
資料分析
首先,我們先取得想要來研究的資料,由於資料授權的問題,目前只能在 finlab平台 上進行程式的撰寫,不過我們近期想到一些方法來避免授權問題,當前請大家不要使用 colab ,而是直接用網頁版來執行,不然會無法運行喔!可以透過以下的程式碼拿到你想要的財報指標,我們以四種財報指標為例:
from finlab import data
menu = """非控制股權 data.get('us_fundamental:accoci') float
資產總額 data.get('us_fundamental:assets') float
流動資產 data.get('us_fundamental:assetsc') float
非流動資產 data.get('us_fundamental:assetsnc') float
"""
with data.us_universe('Common Stock'):
code = menu.split('\t')[1::3]
name = [n.replace('\n', '') for n in menu.split('\t')[0::3]]
for n, c in zip(name, code):
dfs[n] = eval(c)接下來,我們想要進行資料處理,讓財報資料做斜率、取變異等方法,提取出可能有效的資料:
new_feat_dfs = {}
for fname, df in dfs.items():
if df.dtypes[0] != 'float64':
continue
print(fname)
avg2 = df.average(2)
avg4 = df.average(4)
new_feat_dfs[fname + '_avg2'] = avg2
new_feat_dfs[fname + '_avg4'] = avg4
new_feat_dfs[fname + '_diff4'] = df / df.shift(4)
new_feat_dfs[fname + '_1_avg4'] = df / avg4
new_feat_dfs[fname + '_avg2_avg4'] = avg2 / avg4
new_feat_dfs[fname + '_avg2_diff4'] = avg2 / avg2.shift(4)
new_feat_dfs[fname + '_avg4_diff4'] = avg4 / avg4.shift(4)
new_feat_dfs[fname + '_df_max4'] = df / df.rolling(4).max()
new_feat_dfs[fname + '_df_max8'] = df / df.rolling(8).max()
feat_dfs = {**dfs, **new_feat_dfs}
with data.us_universe('Common Stock'):
feat_dfs['money_flow'] = data.get('us_price:close') * data.get('us_price:volume')
del new_feat_dfs然而我們也不知道這些資料,效果究竟如何,所以可以利用機器學習的方式進行 feature 分析:
from finlab.ml import feature
features = feature.combine(feat_dfs, resample='Q')
# 過濾成交量太小的股票
features = features[features['money_flow'] > 1e7]
features.head()
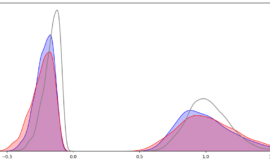
除了有這些財報的特徵外,我們也必須知道這些數值會如何影響將來的股價,所以我們可以將上圖每一個橫軸所對映的未來長跌幅給計算出來,並且計算相關性 corr 假如 1 代表正相關,該數值高意味著未來會上漲,假如是 -1 就代表負相關,數值高反而意味著未來會跌:
from finlab.ml import label
labels = label.return_percentage(features.index, period=60, trade_at_price='open')
corr = features.corrwith(labels).dropna().sort_values()雖然給大家的例子中只有一小部分的資料,但我們自己實驗是產生了 1000 組不同的財報數值。我們只想要提取有用的資料,將其他沒用的資料過濾。也就是我們想找高度相關,或高度負相關的特徵,來進行股票的預測:
print(corr.head(10))
print(corr.tail(10))
上圖發現一些有趣的現象,我們挑最低負相關,與最高相關的來說明。
市值衝吧!
在這個實驗中,「市值_1_avg4」是最高度相關的,其代表的運算方式,是「市值 / 近四季的平均市值」。為什麼近四季市值增加越多,代表未來報酬率越好呢?若一家公司近期的營運表現優於過去,其市值可能會上升,從而使得「市值 / 近四季的平均市值」的比例增加。這也反映了市場對公司未來盈利能力的信心增強。
小心獲利太多啦!
在上圖當中,營收_max4 是最負相關的資訊,代表此數值越高,未來股價越危險,潛在隱含可能營收會有均值回歸的效應產生,導致股價下跌。
數據所代表的含意,跟常識不符合時,如何是好?
當然聽數據的呀!因為金融市場裡並沒有什麼常識可言,以常識來說期貨原油結算應該是正的?(但曾經發生負的狀況)。以常識來說,股價漲太高應該不要再追了(但在台股完全就是要追上去,實驗與實際都如此證明)。為什麼常識不管用?因為在一個效率市場下,任何所謂的「常識」都會被機構交易者各種套利,例如一個常識: ROE 高是好股票,所以當公司發布時,大家知道這個常識而瞬間買入此股票,造成必須要去比拼高頻交易,看誰買的早,就能用比較低的價格買到,才能比別人更早去交易這個「常識」,但對於我這種慢半拍的人來說,當我發現這家公司很好時,股價已經反映了財報,所以這個「常識」就不符合當前科技技術橫行的市場了。雖然速度比不贏別人,那就只好去探勘一些「反常識」,「反常識」沒有人做,所以也是有很多潛在的獲利機會!但是反常識也很容易因為數據處理、探勘的方式不正確,而意外的被產生出來,所以有好的資料驗證步驟,是非常重要的,不過有點離題,我們接著繼續來做策略。
去除相似的資料
在上圖中我們可以看到「市值_1_avg4」以及「市值_df_max4」,其實這兩筆資料是用類似的方法來計算的,雖然都很重要,但只要用其中一種即可,沒必要兩個都用,可以把其中一筆換成其他更有意義的數據,所以我們可以驗證 features 財報數據間的相關性,將相關性高的財報數據給剔除,留下比較有代表性的即可:
import numpy as np
cor_matrix = features[corr.index].corr().abs()
upper_tri = cor_matrix.where(np.triu(np.ones(cor_matrix.shape),k=1).astype(bool))
to_drop = [column for column in upper_tri.columns if any(upper_tri[column] > 0.8)]
long_names = corr[corr.index.isin(to_drop)].tail(30)
short_names = corr[corr.index.isin(to_drop)].head(30)上面程式碼中, 我們找到 long_names 以及 short_names 代表與未來價格高度正相關的指標,以及高度負相關的指標。我們將這些指標對於每個股票去評分,並且加總起來:
from finlab import backtest
score = sum([feat_dfs[f].rank(axis=1, pct=True).fillna(0) for f in long_names.index])
short_score = sum([feat_dfs[f].rank(axis=1, pct=True).fillna(0) for f in short_names.index])
score = score.index_str_to_date()
short_score = short_score.index_str_to_date()就可以得到每個股票的總分了!最後將總分最高的股票做多、最低的股票做空,就可以獲得更穩定的報酬率:
import numpy as np
from finlab.dataframe import FinlabDataFrame
with data.us_universe('Common Stock'):
close = data.get('us_price:close')
vol = data.get('us_price:volume')
cond1 = (close * vol).average(60) > 1e7
cond2 = vol > 5000
cond = cond1 * cond2 * (close.notna())
pos = (FinlabDataFrame(score-short_score) * cond).is_largest(10).astype(int) * 2
neg_pos = (FinlabDataFrame(score-short_score) * cond).is_smallest(20).astype(int)
pos *= close.pct_change().rolling(20).std()
neg_pos *= close.pct_change().rolling(20).std()
pos /= pos.sum(axis=1)
neg_pos /= neg_pos.sum(axis=1)
total_pos = pos - neg_pos
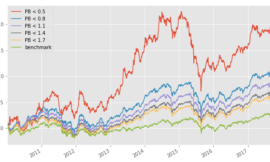
r0 = backtest.sim(total_pos, resample='W', position_limit=0.1)
不過這個策略滿奇怪的,2020年以前都不太會賺,雖然也沒賠太多錢(相較於純做多的策略)但我自己個人會有點忍受不了這麼多年的績效平平,可能還有改進的空間,假如讀者知道為什麼2020 年前後會有這麼大的差異,歡迎留言或在 Discord 跟我們一起討論!