此文章為VIP限定
「希望加入同業本益比及股價淨值比資料,這將對台灣價值股的相關策略研發十分有幫助。 有此資料便可排除產業帶來的本益比及淨值比差異。」
「我想寫成挑出每個低於個別產業平均本益比之個股所組成的投資組合。」
這是 FinLab 高手用戶在 Discord 許願池 寫下的願望,許願池的用意在有些特殊功能在外面的產品找不到,或是程式比較難撰寫,只要你的想法具有研究價值與具體描述,那願望成真不會是夢。
產業面選股加上個股因子的進階策略怎麼開發?馬上來實現~
產業資料
FinLab 的產業主題資料來源主要取自「產業價值鍊資訊平台」。從 FinLab資料庫 只要一行程式碼就能下載全部的細產業資訊。要注意的是此份資料僅限 VIP 使用。
FinLab 其實過去已做過類似分析內容:「本益比選股策略 | 產業因子分析」,不過當時是以證交所一般版塊分類,沒有像 產業價值鍊資訊平台 的分類那麼細緻。

每家公司所屬產業的資訊放在 catergory 內。例如台泥的產業序列裡有主產業的水泥,也有細產業「水泥:水泥成品」(格式為「主產業:細產業」)。

簡單回測範例
如何把「我想寫成挑出每個低於個別產業平均本益比之個股所組成的投資組合。」這個目標變簡單?許多新手覺得程式開發太難的原因是目標複雜,我們可以先將大目標切成幾個小目標。例如先不要想做出每一個產業的投組,先從一個產業開始做,當一個產業測試完沒問題,再來思考重複執行與合併的問題。下面的程式範例以水泥產業為例子進行回測,程式並不難。
from finlab import data
from finlab.backtest import sim
# 取出產業題材
themes = data.get('security_industry_themes')
# 選出產業包含「水泥」公司
ind = themes[themes['category'].str.contains('水泥')]
pe = data.get('price_earning_ratio:本益比')
ind_pe = pe[list(ind['stock_id'].dropna())]
# 計算每日產業本益比中位數
ind_pe_med = ind_pe.median(axis=1)
# 選出本益比小於同業本益比中位數且本益比小於25的公司
position = (ind_pe < ind_pe_med) & (ind_pe < 25)
# 回測
report = sim(position, upload=False)
report.display()
產業因子篩選
簡單範例測完以後,會發現踏出成功的第一步,但接下來還有些問題要處理。
- 有一些產業比較冷門,業內公司太少,統計樣本不夠。
- 產業那麼多,哪一些產業才適合用同業本益比比較法?
- 如何比較產業回測?
取樣統計樣本
流程說明寫在以下程式註解,若你對 python 不熟,有幾個關鍵字需要先熟悉,例如「eval」、「pandas explode」、「pandas groupby」。
依據此程式範例,最後選定 36 個產業來做回測。
# 取出產業題材
themes = data.get('security_industry_themes')
# 複製一個 themes 來計算每個產業內有多少公司?
copied_themes = themes.copy()
# 將 category 陣列從文字格式轉成陣列格式
copied_themes['category'] = copied_themes['category'].apply(lambda s:eval(s))
# 以 pandas 的 explode 展開資料
exploded_themes = copied_themes.explode(['category'])
# 分群產業計算公司數
themes_count = exploded_themes.groupby('category')['stock_id'].count()
# 取出家數大於20家公司的主產業
large_themes = themes_count[themes_count >= 20].index
primary_themes = [i for i in large_themes if ':' not in i]
# primary_themes:
# ['LED照明產業', '交通運輸及航運', '人工智慧', '休閒娛樂', '其他',
# '半導體', '印刷電路板', '大數據', '太空衛星科技', '太陽能產業',
# '平面顯示器', '建材營造', '文化創意業', '汽車', '石化及塑橡膠',
# '紡織', '能源元件', '被動元件', '製藥', '觸控面板',
# '貿易百貨', '資通訊安全', '軟體服務', '通信網路', '連接器', '運動科技',
# '醫療器材', '金融', '鋼鐵', '雲端運算', '電動車輛產業',
# '電子商務', '電機機械', '電腦及週邊設備', '風力發電', '食品', '食品生技']產業面回測比較
接下來要回測36個產業,模擬回測至2018-12-31,用此回測結果選出前n大適合產業,再用選出的產業因子回測 2019 後的數據。
比較36個回測有什麼好工具嗎?很多人可能不知道FinLab早已有工具可用,放在 finlab.optimize 之下的 ReportCollection ,可以產生多策略比較圖表,想了解細節的可以看函數庫文件。
# 模擬回測至2018-12-31,用此回測結果選出前n大適合產業,再用選出的產業模擬
def sim_industry_position_by_pe(ind):
stock_ids = exploded_themes[exploded_themes['category'].apply(lambda s:s==ind)]
pe = data.get('price_earning_ratio:本益比')
ind_pe = pe[list(set(stock_ids['stock_id']))]
ind_pe_med = ind_pe.median(axis=1)
position = (ind_pe < ind_pe_med)
position = position.loc[:'2018']
# 2週換股一次
report = sim(position, upload=False, position_limit=0.2,resample='2W')
return report
# 產生回測組合
reports = {ind: sim_industry_position_by_pe(ind) for ind in primary_themes }
# 放入回測報告組合比較器
collection = ReportCollection(reports)
# 繪圖產業回測報酬率曲線
import plotly.graph_objects as go
fig = go.Figure()
reports = collection.reports
# 報酬率曲線繪圖label按高低排序
dataset = {k: v for k, v in sorted(reports.items(), key=lambda item: item[1].creturn[-1], reverse=True)}
for k, v in dataset.items():
series = v.creturn
fig.add_trace(go.Scatter(x=series.index, y=series.values, mode='lines', name=k, meta=k,
hovertemplate="%{meta}<br>Date:%{x}<br>Creturns:%{y}<extra></extra>"))
fig.update_layout(title={'text': 'Cumulative returns', 'x': 0.49, 'y': 0.9, 'xanchor': 'center',
'yanchor': 'top'})
fig.show()
# 產生回測數據分群柱狀圖
collection.plot_stats().show()
# 產生評分熱力圖
heatmap = collection.plot_stats(mode='heatmap')
heatmap
輸出報酬率曲線,發現表現最好的前15名產業為「’紡織’, ‘電機機械’, ‘大數據’, ‘雲端運算’, ‘醫療器材’, ‘電動車輛產業’, ‘貿易百貨’, ‘食品’, ‘軟體服務’, ‘汽車’, ‘金融’, ‘太陽能產業’, ‘石化及塑橡膠’, ‘資通訊安全’, ‘人工智慧’」,傳產、軟體居多,電子業排名很後面。


一個好多策略不是看報酬率高低就好,ReportCollection 的 熱力圖 將 策略群的數據做分級處理,最後將個指標的分數取平均(最右欄),可以大致先出體質相對前段班的產業回測。前15名大致和報酬率排名差不多。

多產業策略
「假設做出來兩個產業的position,要如何合併?rows數相同, columns數不同,而且columns中stock_id有重複,但是其中的真偽值不同,要作聯集(or)?」
選好產業後,我們可以將每一個產業的訊號部位組裝成一個總合訊號部位,之後回測2019年後的測試集績效。
def get_industry_position_by_pe(ind):
stock_ids = exploded_themes[exploded_themes['category'].apply(lambda s:s==ind)]
pe = data.get('price_earning_ratio:本益比')
ind_pe = pe[list(set(stock_ids['stock_id']))]
ind_pe_med = ind_pe.median(axis=1)
position = (ind_pe < ind_pe_med)
return position
# 選出綜合評分前15高的產業
inds = heatmap.index[:15]
# 部位訊號合併
all_position = pd.concat([get_industry_position_by_pe(ind) for ind in inds],axis=1)
# 處理欄位重複問題,一家公司可能橫跨多產業,只要有一個產業選到,就選入。使用groupby mean處理重複同stock_id
buy = all_position.groupby(level=0, axis=1).mean() > 0
report = sim(buy.loc['2019':], position_limit=0.2,resample='2W',upload=False)
report.display()比較一下2018年前「綜合評分前15高的產業」和「綜合評分前15名之後的產業」,可以發現雖然後者報率比較優(半導體前幾年爆發),但回撤波動比前者高很多,前者除了2020年疫情剛爆發時崩跌,向下波動比較穩定,維持在-10%上下,尤其是空頭年份2022表現比後者穩不少,也較大盤抗跌,牛市時比成長股弱勢,但熊市時有優勢,具價值股特性。
要選前10還是前15名產業,可自由設定。


策略優化
上述產業面選股的回測驗証了價值股特性,但有個問題是選出來的標的太多了,實務上不能能選買,且牛市時動能差了點,所以我們可嘗試加上一些個股條件和流動性條件去限縮標的數量,增加一點成長股因子,讓策略更有實戰能力。台股長期對月營收條件、規模因子友善,是不錯的選項。
加入的個股條件為「近3月平均營收」大於「近12月平均營收」、近月單月營收年增率大於20%、近3月平均營收的年增率大於15%、五日均量大於100張、最後選出符合前述條件五日均量前10小的標的。
策略程式
def get_industry_position_by_pe(ind):
stock_ids = exploded_themes[exploded_themes['category'].apply(lambda s:s==ind)]
pe = data.get('price_earning_ratio:本益比')
stock_ids = [i for i in list(set(stock_ids['stock_id'])) if i in pe.columns]
ind_pe = pe[stock_ids]
ind_pe_med = ind_pe.median(axis=1)
position = (ind_pe < ind_pe_med)
return position
inds = heatmap.index[:15]
all_position = pd.concat([get_industry_position_by_pe(ind) for ind in inds],axis=1)
all_position= all_position.groupby(level=0, axis=1).mean() > 0
vol=data.get('price:成交股數')
close = data.get('price:收盤價')
pe = data.get('price_earning_ratio:本益比')
rev=data.get('monthly_revenue:當月營收')
rev_rf=data.get('monthly_revenue:去年同月增減(%)')
rev_ma3=rev.average(3)
rev_ma12=rev.average(12)
vol_ma5 = vol.average(5)
extra_conds = ((rev_ma3 > rev_ma12).sustain(3)) & (rev_rf >= 20) & (rev_ma3/rev_ma3.shift(12) >= 1.15) & (vol_ma5 >= 100*1000)
buy = all_position & extra_conds
buy *= vol_ma5
buy = buy[buy>0].is_smallest(10)
report = sim(buy, position_limit=0.2,resample='2W',stop_loss=0.2,upload=True)
report.benchmark = data.get('benchmark_return:發行量加權股價報酬指數').squeeze()
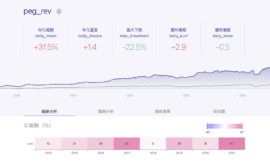
report.display()同業本益比比較法的產業面選股*個股條件的回測結果


單用外加的個股條件的回測結果


回測分析
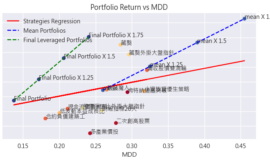
可以發現「同業本益比比較法的產業選股*個股條件」後,年化報酬率、夏普率、勝率表現明顯比「原多產業投組」、「單用外加的個股條件」要好,不僅解決檔數問題,也同時兼備穿越牛熊的能力。
結論
這篇應用跨了許多面向,讓你一次學會:
- 產業資訊處理
- 產業面策略~同業本益比比較法的程式撰寫
- 多策略回測比較報告生成
- 產業面選股*個股基本面的策略優化
是不是很有收穫呢?要知道「產業分析模組」在別家軟體可是要另外付費1000/月的模組功能,「產業面選股主題」的主題在外面課程也要千把塊,沒想到FinLab一個月不到千元的費用就包含了,還外送你「產業面*個股基本面」的策略程式,這絕對在外面軟體的GUI按不出來,學會寫程式,就是有彈性的好處,不用受制於操作介面,也不用學虛無飄渺的操作心法,操盤人多年盤感與產業知識絕對不是你短時間可以複製,但是複製程式卻是很簡單的事…你要選擇哪一個?