此文章為VIP限定
有時我們有了初始策略輪廓,寫出來發現年化報酬率不錯,但夏普率不高、最大回撤率過大,若拿去實戰,持有歷程會遇上信心考驗,績效跳動範圍也大。有沒有辦法讓策略能夠報酬率更高、波動更低? 但選股條件那麼多,單因子策略不停去 try error 組合很沒效率,這時就是”機器學習選股”的優勢,高效分析影響性大的特徵。
很多人對如何將機器學習應用到投資領域很有興趣,但實作要怎麼設計?用報酬率當Label真的好嗎?太難的演算法又看不懂或難消化,到底怎麼辦?
本篇範例會利用基礎的機器學習演算法 Kmeans 分群 mae_mfe 指標,製作決策樹使用的 Labels,優化原本的”本益成長比”策略,示範 scikit-learn 搭配 finlab 模組是多麼強大又簡單!
選定待優化的策略
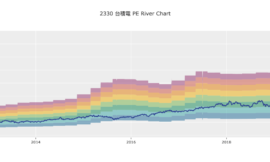
進化後的本益比|本益成長比選股策略 一文中用簡單的單因子回歸產生一個簡潔卻有效的選股策略。為了製造比較多的回測樣本,我們將之前的策略調成每月選取20檔標的。
留意本篇的測試資料結果可能隨著資料集增長而產生差異,回測僅供參考。
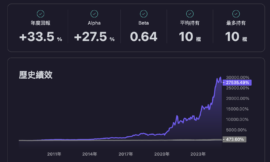
回測年化報酬率23%是不錯的水準,夏普率勉強優於大盤的0.9,但最大回撤率蠻高的,報酬率曲線震盪有點劇烈,好幾次回檔30%,實戰的持有過程肯定會備受考驗,可以加上哪些條件解決波動的問題呢?
from finlab import data
from finlab.backtest import sim
pe = data.get('price_earning_ratio:本益比')
rev = data.get('monthly_revenue:當月營收')
rev_ma3 = rev.average(3)
rev_ma12 = rev.average(12)
營業利益成長率 = data.get('fundamental_features:營業利益成長率').deadline()
peg = (pe/營業利益成長率)
cond1 = rev_ma3/rev_ma12 > 1.1
cond2 = rev/rev.shift(1) > 0.9
cond_all = cond1 & cond2
result = peg*(cond_all)
position = result[result>0].is_smallest(20).reindex(rev.index_str_to_date().index, method='ffill')
report = sim(position=position,name="本益成長比", fee_ratio=1.425/1000/3,upload=True,mae_mfe_window=30,position_limit=0.05)
report.display()
製作波動性 Labels
給對的學習目標很重要!選擇比努力更重要!
一般機器學習選股策略使用報酬率做 label ,但演算法只會判斷報酬率的賺賠高低,並沒有辦法學習波動特性,若給定的 label 一開始就有所限制,再怎麼學也是無法跳脫只追求高報酬的風險。
MAE & MFE
揭開策略的波動面紗|MAE&MFE分析圖組使用指南 一文中解釋了 MAE 與 MFE 的可幫助我們分析策略波動和基本應用,我們可以輕鬆由FinLab模組中的 report.get_trades() 取得策略標的持有歷程的 MAE 與 MFE 與其他交易資料。 report.display_mae_mfe_analysis() 則可顯示波動率分析圖組,幫助我們觀察波動分佈。

從上圖中的 GMFE / MAE 子圖可以發現波動分佈分為三塊:
- 最多聚集的一塊是在左下角小賺小賠的標的。
- 策略獲利的標的有些是「高 GMFE 低 MAE (往上高波動、往下低波動)」,給我們帶來極高獲利,這在趨勢策略較常出現,是我們想保留的。
- 虧損的標的大多是 「低 GMFE 高 MAE (往下高波動、往上低波動)」的族群,有些標的持有紀錄還有 -50% 以上不利跌幅,這些會影響到策略的波動穩定度,是我們想淘汰的拖油瓶。
若能用MAE & MFE 取代報酬率作為 label,就可以讓模型學習判斷波動度與報酬率,若三個分群有特徵共通性,那之後做機器學習可能可找到有效分類 「高 GMFE 低 MAE 」 與 「低 GMFE 高 MAE」的特徵。
Kmeans 分群
如何界定「高 GMFE 低 MAE 」與 「低 GMFE 高 MAE 」 ?
這時非監督學習演算法Kmeans就可以粉墨登場,幫我們去做分群的動作,讓模型自動幫我們藉由 GMFE 低 MAE 兩項特徵分出三個群集。
注意分群給的數字具有隨機性!比如「高 GMFE 低 MAE 」可能分類標註為1,下次執行跳為2。
在模型訓練前,因用有少數大幅獲利與多數群集分太開,先使用 from sklearn.preprocessing import StandardScaler 將資料做正規化,將資料傳入 Kmeans 分群,並將結果繪圖呈現分佈。
我們把預設值 y_pred 放入原本的 trade dataframe,設為 group,就完成 label 標記了,輸出結果可以發現 Kmeans 成功幫我們分出三個顏色區塊。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
def scale_data(data):
scaler = StandardScaler().fit(data)
X_scaled = scaler.transform(data)
return X_scaled
scale_mae = scale_data(trades['mae'].values.reshape(-1, 1))
scale_gmfe = scale_data(trades['gmfe'].values.reshape(-1, 1))
plt.figure(figsize = (8, 8))
random_state = 100
X = np.hstack((scale_mae,scale_gmfe))
y_pred = KMeans(n_clusters=3,random_state=random_state).fit_predict(X)
scatter = plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.legend(*scatter.legend_elements())
plt.title("mae_gmfe kmeans")
plt.xlabel("mae")
plt.ylabel("gmfe")
為了讓模型更專注於「高 GMFE 低 MAE 」與 「低 GMFE 高 MAE 」 的學習,只保留 group 為1、2 (藍綠點) 的部分,我們把白點的區塊視為不影響大局的雜訊,藍色和綠色的點才是影響策略波動的關鍵
cluster_trades = trades.copy()
cluster_trades['group'] = y_pred
cluster_trades['stock_id'] = cluster_trades['stock_id'].apply(lambda s:s[:s.index(' ')])
ana_targets = cluster_trades[cluster_trades['group'].isin([1,2])]
ana_targets = ana_targets.reset_index().set_index(['stock_id', 'entry_sig_date'])決策樹-探索低波動因子
標注完了 label 後,就可以進行下一步,尋找有沒有選股條件能辨識label ,這就要換監督式學習登場。這部分的程式主要參考 Python 理財:打造自己的 AI 股票理專課程 單元 3-7-隨機森林選股策略實作,因資料量級較小,把隨機森林換成決策樹。
製作 Features
將想測試的資料或可能的低波動因子並成 dataframe 準備進入模型訓練,特徵可以使用 Finlab 資料庫 取得,並將資料以 2019 年為分界點,切成訓練及測試資料集。
模型測試結果
將資料集套入 sklearn 決策樹,驗證目標為label=1的集群(低 GMFE 高 MAE ),若找到機率越高,能有效躲避波動。
測試結果放入 confusion-matrix 驗證結果,抓出「低 GMFE 高 MAE 」的準確度達75%,預測45(34+11) 次內有34次正確。
指標意義詳見~Precision, Recall, F1-score簡單介紹。
import pandas as pd
from sklearn import metrics
from sklearn.tree import DecisionTreeClassifier
label = ana_targets[ana_targets['mae']> ana_targets['gmfe']]['group'].values[0]
features_name = list(features.keys())
cf = DecisionTreeClassifier(max_depth=3)
cf.fit(dataset_train[features_name], dataset_train['group'] ==label)
prediction = cf.predict(dataset_test[features_name])
confusion_matrix = metrics.confusion_matrix(dataset_test['group'] == label, prediction)
tn, fp, fn, tp = confusion_matrix.ravel()
confusion_matrix = np.array([[tp, fp],[fn, tn]])
print('f1 score:',metrics.f1_score(dataset_test['group'] == label, prediction))
print('precision score(p):',metrics.precision_score(dataset_test['group'] == label, prediction))
print('recall score(p):',metrics.recall_score(dataset_test['group'] == label, prediction))
plt.figure(figsize=(10, 6))
sns.set(font_scale=2)
ax = sns.heatmap(confusion_matrix, annot=True, cmap='Blues')
ax.set_title('Confusion Matrix with labels\n\n');
ax.set_xlabel('Actual Values')
ax.set_ylabel('Predicted Values');
## Ticket labels - List must be in alphabetical order
ax.xaxis.set_ticklabels(['True','False'])
ax.yaxis.set_ticklabels(['True','False'])
## Display the visualization of the Confusion Matrix.
plt.show()

因子重要性
from sklearn.tree import plot_tree 可繪製出決策樹的機器學習選股決策流程,最上頭的X[8]為’融資使用率’,使用33.6當數值分界點,X序列等同features_name排序。cf.feature_importances_ 可得知重要因子的影響性分數。


優化測試
參考 features_name 、 plot_tree 設定條件數值,加入條件到原本的策略,檢測能否優化。
檔數、部位上限、週期設定不變,只加上選股條件。數據會因資料集擴增而有差異,僅供參考。
低融資使用率
加入 (融資使用率 <= 34) 條件。

低進場波動率
加入 ( entry_volatility <= 0.032) 條件。

低融資使用率 & 低進場波動率

回測分析
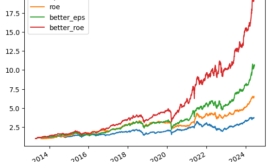
單因子中「低融資使用率」效果最強,明顯提升「夏普率」,「最大回撤率」則變動不大。可能代表原本的策略蠻多虧損或大幅低檔震盪的源在選到高融資使用率的股票,這類股票通常是市場的大波動熱門股,持有者偏向短線操作,很不穩定。
「低進場波動度」雖然讓「年化報酬率」減少,但是「夏普率」和「最大回撤率」提升效果比「低融資使用率」更優。低進場波動度代表買入時波動穩定,比較不會碰上已漲一大段的飛天股之後的乖離過大修正,若之後要加上停損條件,也比較不會在持有初期頻繁停損被洗出場。
「低融資使用率」若與「低進場波動度」因子結合,「夏普率」 從原先策略的 0.9 拉升到1.5,「最大回撤率」降到 -17% 的水準,明顯優化回撤波動。幾乎每一年回測都是正報酬穩定度明顯提升。
結論
這樣的優化策略思路是不是很有趣呢?藉由多元 label 的設定,讓機器學習能考慮多方面去強化策略,只用 scikit learn 最基本的機器學習演算法,非監督式學習與監督式的雙流分工,就能讓優化策略的流程省時省力,趕緊來試試用機器學習選股讓策略更上一層樓吧~
colab 範例檔
低波動本益成長比策略部署