這篇文章介紹一個好用的 package,只要一行,就可以做出精美、詳細的圖表分析
還可以幫你查看資料是否有缺漏和錯誤的情況!


先取得要分析之資料
今天我們來分析一下股票的本益比、股價淨值比和殖利率,
先提供給大家一個爬蟲,讓大家可以直接把資料爬下來:
import datetime
import pandas as pd
import warnings
import requests
from io import StringIO
import pandas_profiling
def crawler(date):
datestr = date.strftime('%Y%m%d')
url = 'https://www.twse.com.tw/exchangeReport/BWIBBU_d?response=csv&date='+datestr+'&selectType=ALL'
res = requests.get(url)
df = pd.read_csv(StringIO(res.text), header=1)
df['本益比'] = pd.to_numeric(df['本益比'], errors='coerce')
return df.dropna(thresh=3).dropna(thresh=0.8, axis=1)接下來我們就呼叫 crawler 這個函式,就可以將財務數據資料都爬取下來囉!
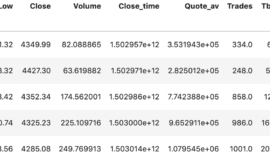
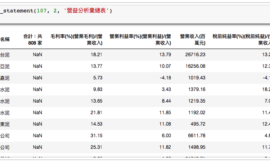
df = crawler(datetime.date(2019,10,7))
df.head()
1. 用舊的方法來分析資料
最簡單的方式,假如有用過 pandas 的大家應該都知道,
可以使用 df.describe() 來大致上觀察數據的樣貌
假如你對 pandas 不太熟悉,它有點像是拿來處理表格的資料,
就像是 python 界的 excel 一樣,雖然它非常好用,但是有點太古老(無聊)了!
df.describe()
2. 酷炫的方法資料分析
首先我們可以安裝 pandas_profiling
pip install pandas_profiling接下來就可以直接來使用:
import pandas_profiling
df = crawler(datetime.date(2019,10,7))
df.profile_report()然後我們就會看到超精美的圖表!
找出資料的缺漏或問題
我覺得 pandas_profiling 很棒的地方在於,
可以將資料一口氣全部統整給我們,方便我們去做資料前處理,
例如下圖中的左下角,就可以看到每一個column有哪些警告,

- 本益比有 20.4 % 是缺漏的:這是正常情況,因為本益比小於零不顯示
- 殖利率有 20.0 % 是 0:這也是正常情況,因為公司不一定有發股利股息
- 財報都是用第 2 季的財報:這也是正常的!
有了這種檢驗,更能夠讓我們知道資料的可靠程度,真的非常非常棒!
除了上述的檢驗外,我們還可以
輕鬆檢視每一個 column 的資料
這邊可以看到每一種資料的分佈,可以讓我們更好的掌握數據分佈型態

檢視資料相關性
這邊還可以檢視資料的相關性,這邊有些複雜的名詞,哪天再來跟各位介紹

pandas_profiling 真的是很不錯的 package,
可以幫我們進一步的認識資料,
假如你也覺得這個 package 很實用,
也歡迎你分享給大家喔!






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}