此文章為VIP限定
量化交易的核心在於數據分析和模型建構,而特徵工程是連接原始數據與模型性能的關鍵環節。隨著數據規模和複雜度的增加,手動特徵工程變得越來越困難且耗時。OpenFE(Open Feature Engineering)作為一個高效的自動化特徵生成工具,為量化交易中的特徵工程提供了全新的解決方案。本文將詳細介紹 OpenFE 的原理,並探討其在量化交易中的應用。
一、OpenFE 簡介
OpenFE 是一個針對表格數據的自動化特徵生成框架,具有以下優勢:
- 高效性:支持並行計算,能夠快速生成大量候選特徵。
- 易用性:僅需幾行代碼即可完成特徵生成和數據轉換。
- 豐富的操作符:涵蓋23種有用且有效的操作符,用於生成候選特徵。
- 多任務支持:適用於二分類、多分類和回歸任務。
- 自動處理缺失值和類別型特徵:無需手動處理數據中的缺失值和類別型特徵。
OpenFE 的有效性已在多個公共數據集上得到驗證,甚至在 IEEE-CIS Fraud Detection Kaggle 比賽中,使用 OpenFE 生成的特徵配合簡單的 XGBoost 模型,擊敗了99.3%的參賽團隊。
OpenFE 原理

這是 OpenFE(Open Feature Engineering)的演算法示意圖,該演算法旨在自動化特徵工程的過程。以下是主要步驟的介紹與講解:
- 資料集 (dataset):
- 首先,將資料集分為數值型特徵 (numerical features)與類別型特徵 (categorical features)。
- 數值型特徵包含連續數值資料,如價格、溫度等;類別型特徵則包含分類資料,如性別、地區等。
- 模型 (model):
- 原始數據會被餵入模型進行訓練,並生成預測結果 (predictions)。這裡的模型可以是任何機器學習模型,如決策樹、隨機森林等。
- 算子 (operators):
- 對數值與類別特徵應用一系列算子進行組合與轉換,這些算子包括基本的數學運算(加、減、乘、除)、統計運算(最小值、最大值)、以及更複雜的操作(如 Combine、GroupBy 等)。這些操作生成候選特徵集 (candidate feature set)。
- FeatureBoost:
- 經過算子轉換後的候選特徵集會通過FeatureBoost進行評估與篩選,旨在提升模型性能。這裡的評估 (Evaluation)包括特徵的重要性分析,修剪 (pruning)和屬性分析 (attribution)則用於移除不重要或重複的特徵。
- 加入最重要特徵 (add top-ranked features):
- 最後,經過篩選後的頂級特徵將被重新加入模型中,以進行下一輪的訓練和優化。
此流程中的關鍵步驟是將特徵自動化生成並經過多次篩選與優化,最終提升模型的預測能力,並減少人工進行特徵工程的工作量。
程式實做
安裝相關套件
!pip install finlab > log.txt
!pip install ta-lib-bin > log.txt
!pip install openfe > log.txt這部分安裝所需的套件:
finlab:提供台灣股市數據及特徵工程模組的工具包。ta-lib-bin:一個技術分析函數庫,專門處理金融數據。openfe:用於自動化特徵工程的套件。
下載資料並且定義函數
from finlab.ml import feature as mlf
from finlab import data
cap = data.get('etl:market_value') # 市值
vol = data.get('price:成交股數') # 成交量
close = data.get('price:收盤價') # 收盤價
benchmark = data.get('benchmark_return:發行量加權股價報酬指數').squeeze() # 大盤- cap:市場價值(市值)。
- vol:成交股數。
- close:收盤價。
- benchmark:台灣加權股價報酬指數,作為市場基準。
avg = lambda n: close / close.average(n)
conv = lambda n: (close / close.shift(n) - 1) * (benchmark / benchmark.shift(n) - 1)
sub = lambda n: (close / close.shift(n) - 1) - (benchmark / benchmark.shift(n) - 1)
bch = lambda n: (close.notna()) * (benchmark / benchmark.shift(n) - 1)
std = lambda n: close.pct_change().rolling(n).std().rank(axis=1, pct=True)定義多個特徵生成函數:
- avg:計算移動平均。
- conv:計算收盤價和基準指數的轉換率。
- sub:收盤價與基準之間的差異
- bch:基準變動。
- std:波動率。
生成特徵
這段程式碼生成一系列新的特徵,並將其按周頻率重新取樣:
包括交易量、移動平均、基準相關差異、波動率等特徵:
features = mlf.combine({
'vol': vol.average(20),
'avg5': avg(5),
'avg20': avg(20),
'avg60': avg(60),
'avg120': avg(120),
'avg250': avg(250),
'sub5': sub(5),
'sub10': sub(10),
'sub20': sub(20),
'sub60': sub(60),
'sub120': sub(120),
'bch5': bch(5),
'bch10': bch(10),
'bch20': bch(20),
'bch60': bch(60),
'bch120': bch(120),
'conv5': conv(5),
'conv10': conv(10),
'conv20': conv(20),
'conv60': conv(60),
'conv120': conv(120),
'std5': std(5),
'std20': std(20),
'std60': std(60),
'cap': cap
}, resample='W')計算預測標籤
利用 finlab.ml.label 計算超額報酬,取樣頻率為 4 週:
from finlab.ml import label as mll
labels = mll.excess_over_mean(features.index, resample='4W')去除缺失,切割訓練與測試集
is_train = features.index.get_level_values('datetime') < '2021-01-01'
notna = (features.isna().sum(axis=1) == 0) & (labels.notna())
train_x = features.loc[is_train & notna]
train_y = labels.loc[is_train & notna]
test_x = features.loc[~is_train & notna]
test_y = labels.loc[~is_train & notna]使用 OpenFE 進行特徵工程
%%capture
from openfe import OpenFE, transform
n_jobs = 4
ofe = OpenFE()
features2 = ofe.fit(data=train_x.reset_index(drop=True),
label=train_y.reset_index(drop=True),
n_jobs=n_jobs,verbose=False, n_data_blocks=128, min_candidate_features=100)
train_x2, test_x2 = transform(train_x.reset_index(drop=True),
test_x.reset_index(drop=True),
features2, n_jobs=1)
train_x2.index = train_y.index
test_x2.index = test_y.index
使用 OpenFE 進行特徵工程,透過自動化生成更多特徵:
- ofe.fit:在訓練資料上進行特徵生成。
- transform:對訓練和測試集進行轉換,應用新生成的特徵。
比對效果,擇優
from openfe import OpenFE, tree_to_formula, transform
import numpy as np
new_features = []
for i, feature in enumerate(ofe.new_features_list):
formula = tree_to_formula(feature)
f_series = feature.calculate(features)
notna = f_series.notna() & labels.notna()
ic = np.corrcoef(f_series[notna].values, labels[notna].values)[0][1]
print(i, formula, ic)
new_features.append((formula, ic))將自動生成的特徵轉換為公式,並計算每個特徵與標籤的相關係數(IC),記錄每個特徵及其IC值。
顯示結果
最終輸出顯示了篩選後的特徵及其與標籤之間的相關係數 (IC, Information Coefficient),並進行排序。以下是最終輸出的部分:
import pandas as pd
pd.DataFrame(new_features).sort_values(1)負向相關特徵 - 其 IC 為負,代表該特徵與股價成負相關
residual(close120) -0.033315
(avg5-conv20) -0.027197
(avg5-conv10) -0.022775
(avg5-conv5) -0.019866
(bch20*conv20) -0.019637
正向相關特徵 - 其 IC 為正,代表該特徵與股價成正相關
min(conv20,conv120) 0.013777
(sub10*bch20) 0.021785
min(conv20,conv60) 0.022378
round(conv120) 0.025027
(bch60/cap) 0.026309結果分析
- 正相關特徵:
(bch60/cap):IC 值為 0.026309,這個特徵表示基準60期變動率與市值之間的比值,這是最具正向預測能力的特徵,能夠幫助識別相對市值較小但基準表現相對強勁的股票。round(conv120):IC 值為 0.025027,代表120期轉換率的四捨五入值,這也是一個有助於預測的正相關特徵,代表轉換率變動具有一定預測力。- 其他:如
min(conv20,conv60)和sub10*bch20這些特徵也展示了正相關,雖然相關性稍低,但仍對預測有幫助。
- 負相關特徵:
residual(close120):IC 為 -0.033315,這是與收盤價120期相關的殘差,表明該特徵與收益有負相關性。換句話說,這類股票的表現可能會較差。- 其他負相關特徵如
(close5-conv20)和(close5-conv10)顯示收盤價與轉換率之間的關係可能不利於預測,這些特徵可能代表潛在的虧損或價格波動的風險。
策略實做
有了上述的新的因子,創建了一個特徵 f,它是基於 bch(60)(60 期基準變動率)與 cap(市值)的比值,表示相對於市值的基準變動。
from finlab.dataframe import FinlabDataFrame
from finlab import backtest
f = bch(60) / cap
pos = f.is_largest(100)
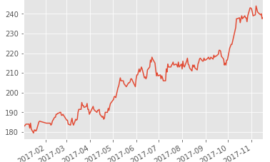
r = backtest.sim(pos, resample='4W', upload=False)
r.display()
延伸討論與結論
本次我們探討了如何利用 OpenFE 進行自動化特徵工程,並運用 Finlab 平台的工具進行金融數據處理與回測。OpenFE 是一個強大的自動化特徵工程工具,它可以從原始數據生成許多複合特徵,並經過篩選來提升模型的預測準確性。其核心流程包括特徵生成、預測、評估、修剪以及重要特徵的篩選,從而減少人工操作的負擔。
透過程式碼的實現,我們首先導入並安裝了所需的套件,包括 finlab、ta-lib-bin、openfe。接著,利用 Finlab 提取台灣股市的數據如市值、成交股數、收盤價以及基準指數,並定義了多個自訂的特徵生成函數,例如移動平均、轉換率、差異和波動率等。這些特徵被結合成一個週期性重取樣的特徵集。
隨後,我們利用 OpenFE 進一步自動化生成新特徵,並根據與標籤的相關性進行篩選。透過相關係數的計算,篩選出對預測最有用的特徵。在經過排序後,最終選出與標籤具有最高正相關的特徵,如 (bch60/cap)。
在回測部分,我們基於所選出的特徵進行了一個簡單的選股策略。利用 bch(60) 與 cap 的比值,選出比值最大的 100 支股票,並使用 Finlab 的 backtest 模組進行回測,設定每 4 週進行一次重取樣,最終展示回測結果,為策略效益提供直觀的分析。
透過這一整套流程,無論是 OpenFE 的特徵生成與篩選,還是 Finlab 的數據處理與回測功能,都展示了其強大的工具性與靈活性,能夠幫助使用者在金融數據分析與量化策略開發中事半功倍。