內容目錄 隱藏 1 本益比河流圖的用途 2 如何繪製? 2.1 生成資料 2.2 繪圖 3 封裝函數與多元應用 […]
此文章為VIP限定
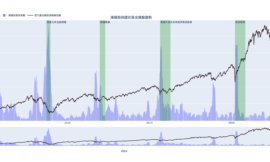
本益比河流圖的用途
取標的一段時間內的本益比上下限,再決定要分割幾層,用來判斷獲利或成長性穩定的股票所處於的本益比區間。
高成長股或獲利不夠穩定的企業不適用,本益比河流圖趨勢變化會太過劇烈。
本益比河流圖上升或層距擴大代表獲利逐漸成長,買在河流圖中下緣是理想位置。
本益比河流圖下降或層距縮小代表獲利逐步下掉,若股價位於河流圖上緣則風險偏高。


如何繪製?
Plotly套件提供了Filled Area Plot函數讓我們可以應用繪製本益比河流圖。
使用Scatter物件帶入fill參數就能將折線圖填充區域顏色。
import plotly.graph_objects as go
# 設定畫布
fig = go.Figure()
# 使用add_trace加入線段
fig.add_trace(go.Scatter(x=[1, 2, 3, 4], y=[0, 2, 3, 5], fill='tozeroy')) # fill down to xaxis
fig.add_trace(go.Scatter(x=[1, 2, 3, 4], y=[3, 5, 1, 7], fill='tonexty')) # fill to trace0 y
fig.show()
我們將步驟拆解為二,第一步是生成繪製所需要的資料,第二步是將資料套入繪圖function。
生成資料
pe/close先求出eps,再用split_range設定本益比上下限要分幾層河流。河流邊界為各區間本益比倍數,與股價相乘後為該邊界本益比對應的股價序列。
from finlab import data
import pandas as pd
stock_id='2330'
#幾層河流
split_range=8
close = data.get('price:收盤價')
pe = data.get('price_earning_ratio:本益比')
df = pe[stock_id]
max_value = df.max()
min_value = df.min()
# 求本益比上下限間距
quan_value = (max_value - min_value) / split_range
# 求本益比各河流倍數
river_borders = [round(min_value + quan_value * i, 2) for i in range(0, split_range + 1)]
# 算出eps
result = (close[stock_id] / df).dropna().to_frame()
index_name = 'pe/close'
result.columns = [index_name]
result['close'] = close[stock_id]
result['pe'] = pe[stock_id]
# 各本益比對應價格
for r in river_borders:
col_name = f"{r} pe"
result[col_name] = result[index_name] * r
result = round(result, 2)資料目標範例如下列dataframe:

繪圖
from finlab import data
import pandas as pd
import plotly.graph_objects as go
import plotly.express as px
df=result.copy()
# 挑出欄位有數字的來畫河流圖,過濾pe/close,close,pe
col_name_set = [i for i in df.columns if any(map(str.isdigit, i))]
fig = go.Figure()
# 執行迴圈填入資料序列
for n, c in enumerate(col_name_set):
# 第一道邊界下不要填充
if n == 0:
fill_mode = None
else:
fill_mode = 'tonexty'
# colors.qualitative.Prism填入河流圖階層顏色
fig.add_trace(
go.Scatter(x=df.index, y=df[c], fill=fill_mode, line=dict(width=0, color=px.colors.qualitative.Prism[n]),
name=c))
# 製作客製化data項目用來製作hovertemplate,顯示浮動資料
customdata = [(c, p) for c, p in zip(df['close'], df['pe'])]
hovertemplate = "<br>date:%{x|%Y/%m/%d}<br>close:%{customdata[0]}" + f"<br>'pe'" + ":%{customdata[1]}"
fig.add_trace(go.Scatter(x=df.index, y=df['close'], line=dict(width=2.5, color='#2e4391'), customdata=customdata,
hovertemplate=hovertemplate, name='close'))
# 取股名製作title
security_categories = data.get('security_categories').set_index(['stock_id'])
stock_name = security_categories.loc[stock_id]['name']
fig.update_layout(title=f"{stock_id} {stock_name} {'PE'} River Chart",
template="ggplot2",
yaxis=dict(
title='price',
),
# hovermode='x unified',
)
# 顯示十字線
fig.update_xaxes(showspikes=True)
fig.update_yaxes(showspikes=True)注意以下程式,若第一道邊界下沒設None,會變成以下形式,最低一層會被填入很大一塊區域,與河流間距不相符,有礙觀察,因此我們要讓第一道邊界以下不要填充才比較好。
for n, c in enumerate(col_name_set):
fill_mode = 'tonexty'
封裝函數與多元應用
除了本益比河流圖,常用的還有股價淨值比河流圖,計算和應用方式和本益比河流圖大同小異,我們可以將上面的程式封裝成函數,設定一個mode參數去選擇我們要哪一種河流圖。
完整程式如下:
from finlab import data
import pandas as pd
import plotly.graph_objects as go
import plotly.express as px
# 控制資料範圍
def df_date_filter(df, start=None, end=None):
if start:
df = df[df.index >= start]
if end:
df = df[df.index <= end]
return df
def get_pe_river_data(start=None, end=None, stock_id='2330', mode='pe', split_range=6):
if mode not in ['pe', 'pb']:
print('mode error')
return None
close = df_date_filter(data.get('price:收盤價'), start, end)
pe = df_date_filter(data.get('price_earning_ratio:本益比'), start, end)
pb = df_date_filter(data.get('price_earning_ratio:股價淨值比'), start, end)
df = eval(mode)
if stock_id not in df.columns:
print('stock_id input is not in data.')
return None
df = df[stock_id]
max_value = df.max()
min_value = df.min()
quan_value = (max_value - min_value) / split_range
river_borders = [round(min_value + quan_value * i, 2) for i in range(0, split_range + 1)]
result = (close[stock_id] / df).dropna().to_frame()
index_name = f'{mode}/close'
result.columns = [index_name]
result['close'] = close[stock_id]
result['pe'] = pe[stock_id]
result['pb'] = pb[stock_id]
for r in river_borders:
col_name = f"{r} {mode}"
result[col_name] = result[index_name] * r
result = round(result, 2)
return result
def plot_tw_stock_river(start=None, end=None, stock_id='2330', mode='pe', split_range=8):
"""Plot River chart for tw_stock
Use maximum or minimum PE(PB) to calculate River.
it is good for judging the high and low in the historical interval.
Args:
start(str): The date of data start point.ex:2021-01-02
end(str):The date of data end point.ex:2021-01-05
stock_id(str): Target id in tw stock market ex:2330.
mode(str): 'pe' or 'pb'.
split_range(int):the quantity of river borders.
Returns:
figure
"""
df = get_pe_river_data(start, end, stock_id, mode, split_range)
if df is None:
print('data error')
return None
col_name_set = [i for i in df.columns if any(map(str.isdigit, i))]
fig = go.Figure()
for n, c in enumerate(col_name_set):
if n == 0:
fill_mode = None
else:
fill_mode = 'tonexty'
fig.add_trace(
go.Scatter(x=df.index, y=df[c], fill=fill_mode, line=dict(width=0, color=px.colors.qualitative.Prism[n]),
name=c))
customdata = [(c, p) for c, p in zip(df['close'], df[mode])]
hovertemplate = "<br>date:%{x|%Y/%m/%d}<br>close:%{customdata[0]}" + f"<br>{mode}" + ":%{customdata[1]}"
fig.add_trace(go.Scatter(x=df.index, y=df['close'], line=dict(width=2.5, color='#2e4391'), customdata=customdata,
hovertemplate=hovertemplate, name='close'))
security_categories = data.get('security_categories').set_index(['stock_id'])
stock_name = security_categories.loc[stock_id]['name']
fig.update_layout(title=f"{stock_id} {stock_name} {mode.upper()} River Chart",
template="ggplot2",
yaxis=dict(
title='price',
),
# hovermode='x unified',
)
fig.update_xaxes(showspikes=True)
fig.update_yaxes(showspikes=True)
return fig
# plot_tw_stock_river(stock_id='2330',mode='pe',split_range=8)
plot_tw_stock_river(stock_id='2330',mode='pb',split_range=8)
總結
使用finlab和plotly套件可以做出各式各樣視覺化的應用,只要學會一些小技巧,就能客製化屬於自己的看盤工具。
對本篇程式有興趣的可以參考文底連結附檔,記得要先註冊Finlab量化平台才可有權限使用程式喔!