籌碼數據豐富是台股一大特色,像美國只有「每季」公告的 13F 報告揭露大機構(資產管理規模超過 1 億美元)的資金動向,且截止申報日是每個季度 (三個月) 結束之後的 45 天之內,實在落後太久,很難當即時指標。
但台股則是有日週期的「法人買賣超」、「融資融券」、「借還券」、「當沖」、「分點券商進出」…,週週期的則有本篇要抓的「集保戶股權分散表」、月週期則有「董監內部人持股變動與質押」,可說有許多工具可分析籌碼。
集保餘額可以幫助我們判斷不同持股分級的持股者間的資金流動變化,每週公佈的特性可當較同步的指標,也減低日週期資料如「分點籌碼」的雜訊。
分析前得先要有資料,讓我們開始執行我們的Python爬蟲吧!
內容目錄
隱藏
資料源
台灣集中保管結算所 簡單說就是統計籌碼的單位,服務項目包括有價證券集中保管帳簿劃撥、集中交易及櫃檯買賣市場有價證券交割、興櫃股票款券結算交割、期貨結算電腦處理、無實體有價證券登錄、參加人有價證券電腦帳務處理等,並接受金融監督管理委員會證券期貨局委託辦理股務查核作業。
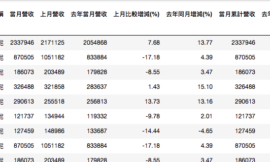
「集保戶股權分散表」是官方公開資料,每週六早上有新數據,資料查詢分兩種,一種是單一標的歷史資料查詢 (資料僅1年份) ; 另一種是總表查詢,可以一次抓全部資料,要注意總標指提供單週資料。所以若要歷史數據得自己每一檔慢慢搜集,或參考 FinLab 資料庫。

Python爬蟲程式範例
「集保戶股權分散表」爬蟲的資料處理細節見註解。
def crawl():
# 將網站回傳資料轉到 read_csv 解析,加入 headers 的功能為防止反爬蟲辨識,官方有時會擋
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_1\
0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
res = requests.get("https://smart.tdcc.com.tw/opendata/getOD.ashx?id=1-5", headers=headers)
df = pd.read_csv(StringIO(res.text))
df = df.astype(str)
df = df.rename(columns={
'證券代號': 'stock_id',
'股數': '持有股數', '占集保庫存數比例%': '占集保庫存數比例'
})
# 移除「公債」相關的id
debt_id = list(set([i for i in df['stock_id'] if i[0] == 'Y']))
df = df[~df['stock_id'].isin(debt_id)]
# 官方有時會有不同格式誤傳,做例外處理
if '占集保庫存數比例' not in df.columns:
df = df.rename(columns={'佔集保庫存數比例%': '占集保庫存數比例'})
# 持股分級=16時,資料都為0,要拿掉
df = df[df['持股分級'] != '16']
# 資料轉數字
float_cols = ['人數', '持有股數', '占集保庫存數比例']
df[float_cols] = df[float_cols].apply(lambda s: pd.to_numeric(s, errors="coerce"))
# 抓表格上的時間資料做處理
df['date'] = datetime.datetime.strptime(df[df.columns[0]][0], '%Y%m%d')
#只要第二層欄位名稱
df = df.drop(columns=df.columns[0])
# 索引設置 unique index
df = df.set_index(['stock_id', 'date', '持股分級'])
return df輸出格式

未來開發
Python爬蟲蒐集完資料後,我們就可以用資料來撰寫策略或做資料視覺化~究竟「集保戶股權分散表」有沒有用?讓我們繼續看下去。
了解更多 爬蟲實做 ~